Embedding 是机器学习领域中的一个概念,主要用于将高维的数据嵌入到低维空间,以便于算法更好地处理和理解数据。通常用于将离散的、高维的特征转换为连续的、低维的向量表示
Word2Vec 算法
Word2Vec 是一种用于词嵌入的算法,它基于分布式假设:假设上下文相似的单词在语义上也是相似的。Word2Vec 有两种主要的训练模型:CBOW(连续词袋模型)和 Skip-gram(跳字模型)
-
模型
-
CBOW (上下文 -> 中心)
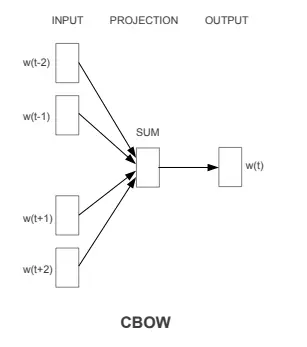
CBOW 由 Tomas Mikolov 等人在2013年提出。其目标是通过上下文的单词来预测目标词,它将上下文单词的词向量平均或求和,然后利用这个上下文向量来预测中心词的向量
-
架构
-
输入层:上下文单词的 one-hot 编码
-
嵌入层:将上下文单词的 one-hot 转换为词向量,并进行平均或求和得到上下文向量
-
Softmax 层:输出中心词的概率分布
-
损失函数:通常使用交叉熵来计算预测词和真实词之间的误差
-
-
优点
能够利用大规模语料库进行训练,学习到高质量且低维度的稠密向量,捕捉单词之间的复杂关系
-
缺点
忽略了上下文单词的顺序,对低频或生僻单词可能无法生成准确的词向量,需要大量的训练时间和内存空间
-
-
Skip-gram(中心 -> 上下文)
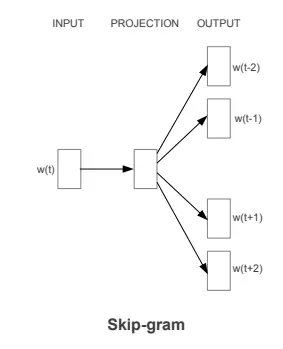
Skip-gram 跳字模型是 word2vec 算法中的另一种模型,与 CBOW 相反。skip-gram 模型的目标是使用一个单词(中心词)来预测它周围的单词
-
架构
-
输入层:中心词的 one-hot 编码
-
嵌入层:中心词的词向量
-
Softmax 层:上下文单词的概率分布,表示中心词预测为该该上下文单词的概率
-
损失函数:通常使用交叉熵计算预测概率分布和真实分布之间的误差
-
-
优点
能够更准确地捕捉到罕见单词的上下文信息,因为它直接利用中心词来预测每个上下文词。这使得它在处理较小的语料库或者需要精确捕捉单词上下文信息的任务时表现更好
-
缺点
计算复杂度较高,特别是当词汇表很大时,因为每个中心词都需要对所有可能的上下文词进行预测。此外,对于高频词,它可能会过度强调这些词的常见上下文,而忽略掉一些不常见的但可能同样重要的上下文信息
-
-
-
Embedding 过程
训练好的 Word2Vec 模型有一张词表,词表中包含训练数据中所有单词所对应的词向量,当使用 Word2Vec 将句子转化为向量时,一种常见的方法是将句子中所有单词的词向量取平均或加权平均。这可以帮助将整个句子的语义信息编码到一个向量中。大致步骤如下
-
获取每个单词的词向量,将句子中的每个单词都映射到 Word2Vec 模型中的词向量空间,得到对应的词向量
-
计算平均向量:将所有单词的词向量取平均,得到句子的平均向量,其中每个维度代表了句子在对应语义维度上的平均值。这个向量可以用于表示句子的语义特征

-
-
那么如何训练一个 Embedding 模型
之前提到模型词表中已经存储了词向量,因此句子可以被分词之后到词表中找到对应词的词向量做加权平均得到句子的向量表示,那么词表中的词向量是从哪来的?
-
训练模型
-
准备数据
将文本分解为词语序列,构建词汇表,并为词汇表中的每个词分配初始的词向量。这些初始的词向量通常是随机的,这些随机初始化的词向量没有任何具体语义含义,它们只是作为模型训练的起点。随机初始化词向量的原因是,在开始训练之前,模型并不知道每个词汇的语义信息。通过随机初始化,模型有了一个初始状态,然后通过训练过程逐步调整这些词向量,使它们能够捕捉到词汇之间的语义关系。随机初始化的词向量可以是服从某种分布的随机数,比如均匀分布或正态分布。这些初始向量会在训练过程中逐渐调整,以使模型在预测上下文词汇时更准确。一个好的 Embedding 模型拥有海量 (GB,TB,PB) 的文本作为训练数据,同一个词出现的句子越多,其 Embedding 越接近真实语义
-
滑动窗口,切分文本
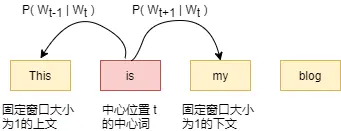
对于一段文本,从第一个词开始以固定的窗口大小对文本进行滑动切分,计算每个词出现的概率,每个词会拥有两个概率值,一个是作为中心词出现的概率,另一个是作为上下文时出现的概率对应的,每个词将拥有两个向量表示,一个表示该词作为中心词,另一个表示该词作为上下文
-
预测概率分布
模型会根据输入的中心词或上下文词的词向量,计算每个词汇成为目标的概率。然后,使用 Softmax 对这些概率进行归一化处理, 这个概率分布表示给定上下文条件下,每个词汇成为中心词或上下文词的概率。这个分布会被用于计算损失函数,进而用于优化模型的权重
-
反向传播,更新权重
-
示例代码
from gensim.models import Word2Vec from gensim.models.word2vec import LineSentence import nltk nltk.download('punkt') sentences = LineSentence('text.txt') # 训练 Word2Vec 模型 # vector_size 是你想要的词向量的维度 # window_size 是上下文窗口的大小 # min_count 是词频的最小阈值,低于此值的词将被忽略 # workers 是训练的工作线程数 model = Word2Vec(sentences, vector_size=100, window=5, min_count=5, workers=4) # 保存模型 model.save("word2vec.model") # 加载模型 model = Word2Vec.load("word2vec.model") # 获取单词 'computer' 的词向量 vector = model.wv['computer'] # 找到与 'computer' 最为相似的 10 个单词 similar_words = model.wv.most_similar('computer', topn=10)
-