随着移动互联网的飞速发展,人们已经处于一个信息过载的时代。在这个时代中,信息的生产者很难将信息呈现在对它们感兴趣的信息消费者面前,而对于信息消费者也很难从海量的信息中找到自己感兴趣的信息。推荐系统就是一个将信息生产者和信息消费者连接起来的桥梁。平台往往会作为推荐系统的载体,实现信息生产者和消费者之间信息的匹配。
系统架构
推荐系统架构,首先从数据驱动角度,对于数据,最简单的方法是存下来,留作后续离线处理,离线层就是我们用来管理离线作业的部分架构。在线层能更快地响应最近的事件和用户交互,但必须实时完成。这会限制使用算法的复杂性和处理的数据量。离线计算对于数据数量和算法复杂度限制更少,因为它以批量方式完成,没有很强的时间要求。不过,由于没有及时加入最新的数据,所以很容易过时。
个性化架构的关键问题,就是如何以无缝方式结合、管理在线和离线计算过程。近线层介于两种方法之间,可以执行类似于在线计算的方法,但又不必以实时方式完成。这种设计思想最经典的就是Netflix在2013年提出的架构,整个架构分为
- 离线层:不用实时数据,不提供实时响应;
- 近线层:使用实时数据,不保证实时响应;
- 在线层:使用实时数据,保证实时在线服务;
设计思想
这个架构为什么要这么设计,本质上是因为推荐系统是由大量数据驱动的,大数据框架最经典的就是lambda架构和kappa架构。而推荐系统在不同环节所使用的数据、处理数据的量级、需要的读取速度都是不同的,目前的技术还是很难实现一套端到端的及时响应系统,所以这种架构的设计本质上还是一种权衡后的产物,所以有了下图这种模型:
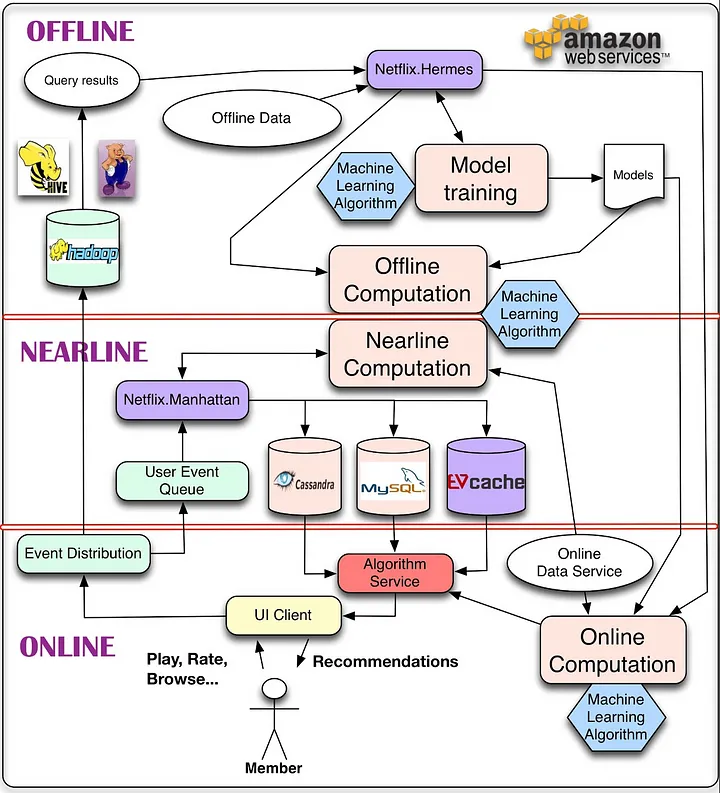
整个数据部分其实是一整个链路,主要是三块,分别是客户端及服务器实时数据处理、流处理平台准实时数据处理和大数据平台离线数据处理这三个部分。
首先是客户端和服务端的实时数据处理。这个很好理解,这个步骤的工作就是记录。将用户在平台上真实的行为记录下来,比如用户看到了哪些内容,和哪些内容发生了交互,和哪些没有发生了交互。如果再精细一点,还会记录用户停留的时间,用户使用的设备等等。除此之外还会记录行为发生的时间,行为发生的session等其他上下文信息。
这一部分主要是后端和客户端完成,行业术语叫做埋点。所谓的埋点其实就是记录点,因为数据这种东西需要工程师去主动记录,不记录就没有数据,记录了才有数据。既然我们要做推荐系统,要分析用户行为,还要训练模型,显然需要数据。需要数据,就需要记录。
第二个步骤是流处理平台准实时数据处理,这一步是干嘛的呢,其实也是记录数据,不过是记录一些准实时的数据。很多同学又会迷糊了,实时我理解,就是当下立即的意思,准实时是什么意思呢?准实时的意思也是实时,只不过没有那么即时,比如可能存在几分钟的误差。这样存在误差的即时数据,行业术语叫做准实时。那什么样的准实时数据需要记录呢?在推荐领域基本上只有一个类别,就是用户行为数据。也就是用户在观看这个内容之前还看过哪些内容,和哪些内容发生过交互。理想情况这部分数据也需要做成实时,但由于这部分数据量比较大,并且逻辑也相对复杂,所以很难做到非常实时,一般都是通过消息队列加在线缓存的方式做成准实时。
第三个步骤,叫做离线数据处理,离线也就是线下处理,基本上就没有时限的要求了。
一般来说,离线处理才是数据处理的大头。所有“脏活累活”复杂的操作都是在离线完成的,比如说一些join操作。后端只是记录了用户交互的商品id,我们需要商品的详细信息怎么办?需要去和商品表关联查表。显然数据关联是一个非常耗时的操作,所以只能放到离线来做。