自动文本生成的早期研究长期聚焦于相对较短的文本单元. 不论是机器翻译中的句子、问答系统中的答案,还是早期故事生成中的简短段落,其核心挑战主要围绕局部流畅性、语法正确性和语义准确性。然而,当生成目标从五句话或一两个段落 扩展到数千词的短篇小说时,问题的性质发生了根本性的变化. 随着文本长度的增加,一系列新的、更高层次的挑战浮出水面,其中最核心的便是全局连贯性: 一个由数千词构成的故事不再仅仅局限于每个句子或每个段落的流畅, 更需要关注的是这些局部单元如何共同构建一个有机统一的整体. 这包括一个贯穿全文的主线, 角色人设的内在逻辑, 世界观的一致性等, 如何让生成式模型在数千个时间步 (token) 跨度上保持对高级叙事结构的记忆和遵循, 这成为了当前 NLP 领域的重要难题…
Paper: Re³: Generating Longer Stories With Recursive Reprompting and Revision
早期实践
在 Re³ 提出之前, 已有的方法在尝试生成长篇叙事时, 普遍会陷入几种典型的失败模式:
-
情节与主旨完整性的丧失: 这是最常见的失败模式, 一个系统在故事的开篇可能能够很好地遵循用户给定的初始前提(premise),但随着文本的不断生成,叙事线索会逐渐“漂移”。故事可能会偏离最初设定的核心冲突,引入无关的角色或事件,最终导致结尾与开头的主旨毫不相干. 这种漂移现象的根源在于,模型缺乏一个明确的、长期的“叙事蓝图”来约束其生成过程.
-
事实与风格缺乏一致性: 例如,一个角色的眼睛颜色在故事前后发生变化,一个在早期情节中被摧毁的关键物品在后期又突然出现,或者一个角色的能力设定前后不一(例如,一个最初被描述为几乎无敌的变种人,后来却能被普通手段轻易杀死 )。同样,在数千词的跨度上保持统一的叙事风格(narration style)也极为困难 。模型可能会在正式的第三人称叙述和非正式的口语化描述之间摇摆,破坏了故事的沉浸感.
-
大语言模型并非 “开箱即用”: 人们曾期望大语言模型强大的零样本(zero-shot)能力能够自然地解决长篇生成问题。然而,现实恰恰相反。即使是当时最先进的通用预训练语言模型,在没有经过特定微调或架构引导的情况下,仍然难以胜任复杂的长篇生成任务, 其输出往往会变得内容混乱、逻辑跳跃,并且在主题上不断重复,缺乏有意义的情节推进. 这背后反映了一个问题: LLMs的核心机制是基于局部上下文预测下一个词元,这种机制天然地使其擅长维持局部流畅性。然而,诸如“整体情节”、“主旨相关性”和“长程事实一致性”等属性,是文本的全局属性,而非局部属性。一个LLM可以写出一个优美的段落,但这个段落可能在不经意间与十章之前的一个细节相矛盾,或者缓慢地偏离故事的核心主题.
为了解决以上问题, 早期研究提出了 “Human in the loop” 范式, 通过在关键节点(如规划, 修改, 决策)中引入人类干预来引导模型进行正确输出, 例如由 AI 生成故事草稿, 再由人类用户选择最佳的续写方向或修正情节漏洞. 这种范式通过牺牲可扩展性和自主性, 换取更高的输出质量和可控性. 而 Re³ 追求的则是自动机, 构建一个能够从头到尾独立完成创作任务的自洽系统.
Re³ 系统设计
Re³ 的核心思想并非构建一个极其强大的单一模型, 而是设计一个精巧的多阶段系统, 通过模拟人类作家的创作流程来引导一个现有的大语言模型完成长篇故事的生成.
这种模式的本质是“分而治之”,将一个宏大、无结构的目标分解为一系列可管理、有结构的子任务.
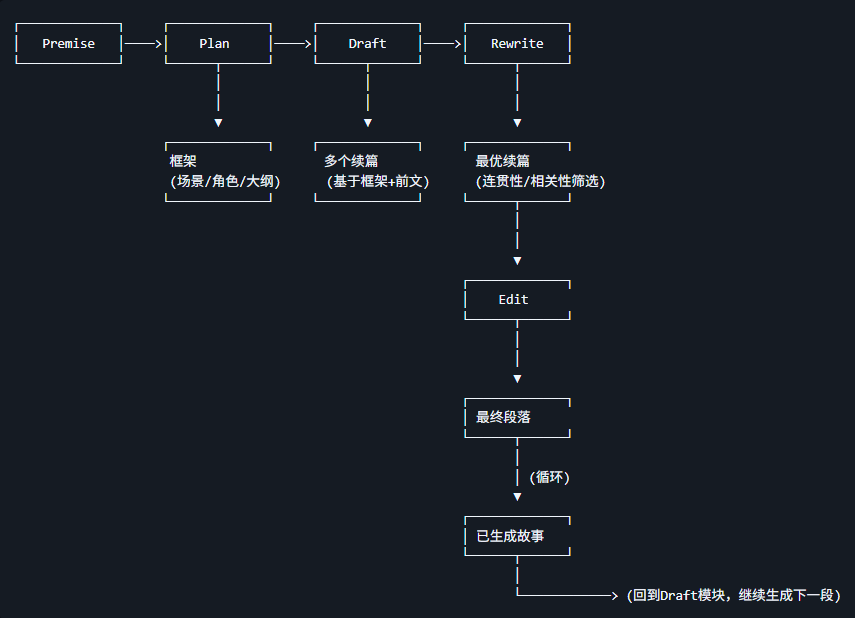
Re³ 系统概览
Re³ 主要由 4 个模块构成:
-
Plan (规划): 生成最高层级的故事结构
通过提示(Prompting)一个通用 LLM,根据给定的前提,生成故事的背景设定、角色列表和多点式情节大纲.
-
输入: 初始前提 (Premise)
-
处理: 基于 Premise 生成故事的结构化框架, 包括
场景 (Setting)角色 (Characters)大纲/关键情节节点 (Outline) -
输出: 结构化的故事框架, 作为后续生成的蓝图
-
-
Draft (起草): 根据计划生成故事段落
递归式提示 (Recursive Reprompting):在每一步动态地将来自计划、前提和已有故事的上下文信息注入到 LLM 的提示中.
-
输入: Plan 模块的输出, 即故事框架, 以及已生成的故事内容
-
处理: 基于框架和前文生成故事段落
-
从故事框架中提取与当前情节相关的信息 (如当前的大纲节点, 相关角色描述)
-
整合前文内容 (近期情节摘要, 上一段落原文)
-
提示语言模型生成固定长度的续篇
-
-
输出: 多个可能的故事续篇 (文中为 10 个)
-
-
Rewrite (重写): 通过选择最佳续写来提升连贯性和相关性
对多个候选段落进行重排序(Reranking),评估其与前文的连贯性以及与当前大纲要点的相关性.
本阶段涉及一个 Reranker 模型:
-
训练数据: Hugging Face 链接
-
训练方法: 监督学习
-
输入: Draft 模块生成的多个续篇
-
处理: 通过重排序和过滤筛选最优的续篇
-
连贯性排序 (Coherence Reranker), 用 Longformer 模型判断续篇与前文的逻辑连贯性.
-
相关性排序 (Relevance Reranker), 判断续篇是否符合当前大纲节点和初始前提.
-
启发式过滤: 移除重复内容, 叙事视角突变, 语法错误等问题.
-
-
输出: 最优续篇
-
-
Edit (编辑): 修正局部的、事实性的不一致
维护一个角色属性字典, 检测并修正新段落中出现的矛盾之处.
本阶段涉及一个 Binary Classifier 模型, 该模型被训练用于判别一个文段是否需要被编辑.
-
输入: Rewrite 模块选出的最优续篇
-
处理: 检测并修正长程事实不一致
-
提取角色属性, 从续篇中提取角色的关键属性 (如年龄、职业、关系,通过 GPT-3-Instruct 生成事实列表并转化为属性 - 值对).
-
检测矛盾, 与历史属性字典对比,用 Entailment 模型 (文本蕴含, 如 BART-Large) 判断是否存在矛盾 (如前文说 “Peyton 是女性”,续篇写成 “他的餐厅”)
Entailment 模型即文本蕴含模型,是 NLP 领域中的一种模型,用于判断一个句子是否可以从另一个句子推断出来。它试图将一个有序的句子对分类为 “positive entailment”(肯定蕴含,第一个句子能证明第二个句子正确)、“negative entailment”(否定蕴含,第一个句子否定第二个句子)或 “neutral entailment”(中性,两个句子无关联)三种类别中的一种.
-
修正矛盾, 通过预训练 LLM 如 GPT-3 修改矛盾内容 (如将”他的餐厅”改为”她的餐厅”)
-
-
输出: 经过事实修正的最终段落
-
Re³ 相比于早期工作的创新点
-
零样本规划与起草: Re³ 的一个关键创新点在于其规划和起草模块完全是零样本的, 即它们没有在任何故事数据集上进行微调, 这种零样本方法是直接针对先前工作中存在的领域和长度限制问题的解决方案. 通过不依赖于特定的语料库, 该系统摆脱了该语料库在风格和长度上的偏见, 从而使其能够生成“比先前工作长一个数量级”的故事. 这使其能够生成更多样化、更长篇的叙事, 而不受限于训练数据的范围.
-
递归式提示: 这是起草模块的核心机制,也是对“链式思维”(Chain-of-Thought)提示范式的一种泛化 。在生成每一个新的故事段落时,系统并非简单地将之前的文本作为上下文。相反,它会动态地、有选择性地从多个信息源(初始前提、全局大纲、角色设定、以及最近生成的内容)中提取最相关的信息,重新构建一个高度情境化的提示. 这个过程可以被理解为一个动态的、有状态的上下文管理系统. 它通过在有限的上下文窗口内,不断地提醒 LLM 全局计划和遵循历史, 有效地防止了叙事“漂移”问题的发生, 从而在局部生成步骤中强制注入了全局意识.
-
混合系统设计: 其结合了无需数据的零样本模块 (规划、起草) 和依赖于数据的有监督模块 (重写、编辑), 这种设计利用零样本提示的灵活性和通用性进行了创造性的工作, 同时利用了监督学习的方法来执行目标明确且需要确定性的评估任务.
Re³ 的局限性
尽管Re3取得了突破,但它远非完美, 文中列举了该系统当前存在的诸多局限:
-
评估瓶颈: 作者坦言,进一步提升故事长度的“最大障碍”是评估本身. 对数千词的故事进行高质量的人类评估, 既昂贵又耗时, 且评估结果本身也存在噪声 (不同评估者的主观判断差异). 这直接限制了实验的样本规模,使得进行更详尽的消融研究实验 (ablation studies) 变得不切实际.
这一局限性超越了 Re³ 本身,直接揭示了整个领域的一个深层困境. 目前业界和学界均没有针对“情节连贯性”、“主题一致性”等长程属性的可靠自动评估指标,使得整个领域的研究迭代都异常缓慢和昂贵.
-
表现不佳的编辑模块: 尽管编辑模块被设计用于解决事实不一致的问题,但实验数据显示,它对整体情节连贯性和前提相关性这两个核心指标的贡献微乎其微 。即便在一个专门设计的受控环境中,其检测基于角色属性矛盾的绝对性能也仍然很低 (ROC-AUC 得分仅为 0.684).
编辑模块试图将硬性的、符号化的逻辑(例如,属性X的值是Y,就不能是Z)强加于一个软性的、概率性的模型(LLM)的输出之上. LLM并不像数据库那样“存储”事实;一个角色的属性是一种弥散在网络激活模式中的概率分布,而非一个离散的表格条目. 编辑模块的低性能表明,将一个符号检查器“嫁接”到一个概率生成器上是困难的. 生成器可能以检查器无法捕捉的微妙方式表达矛盾,或者检查器的修正行为本身可能会破坏叙事的流畅性。这一现象暗示,后处理式的修正(post-hoc editing)可能是一个有缺陷的范式. 一个更有前景的方向,正如作者在呼吁改进长程连续性时所暗示的 ,是构建那种将一致性作为生成过程内在属性的模型,而非一个事后的补丁. 这可能需要整合了记忆或知识库的全新模型架构.