Gemini 是谷歌开发的多模态大模型系列,自 2023 年 12 月发布以来,已迭代至 2.5 版本,包含 Gemini 2.5 Pro、Flash、Flash-Lite、Live 等细分型号,覆盖从云端到移动端的全场景需求. 作为谷歌的旗舰模型家族, Gemini 在多个 NLP 任务上表现优异, 在文学内容创作上更是展示出了出类拔萃的性能. 而近期, 谷歌开放开发者用户对 Gemini 的微调接口, 使得我们作为下游研究/应用的开发者, 得以使用私有数据对 Gemini 进行定制化调优.
谷歌对 Vertex AI 的模型微调模块的文档零碎且更新不及时, 我第一次对着官方文档初探 Vertex AI 模型微调功能时也是一头雾水, 好在我摸索出了正确的使用方式, 并在此总结我的经验.
在此, 假设我的读者均具备了 SFT, DPO, RL 等迁移学习算法的技术背景, 我将省略迁移学习理论, 直接进入实操部分.
以 Gemini 2.5 Pro 为基线模型, 应用 SFT (监督微调)
-
在 GCP (谷歌云) 完成你的预备工作
首先, 你需要一个谷歌账户 (假设你已注册), 并登录 GCP 平台.
登陆后, 主页面如下:
点击主页右上角的
控制台链接, 进入项目控制台:
若你第一次使用 GCP, 请为你的实验创建一个项目 (点击左上角项目按钮, 在此处显示为
RL-GenAI):
新建项目后, 回到项目控制台页, 并点击
查看所有产品按钮, 进入产品页
选择
人工智能类别, 找到Vertex AI链接并点击. 现在, 我们进入了Vertex AI平台主页:
在
Vertex AI平台主页的左侧找到调优二字, 并点击, 我们则进入了模型微调功能模块: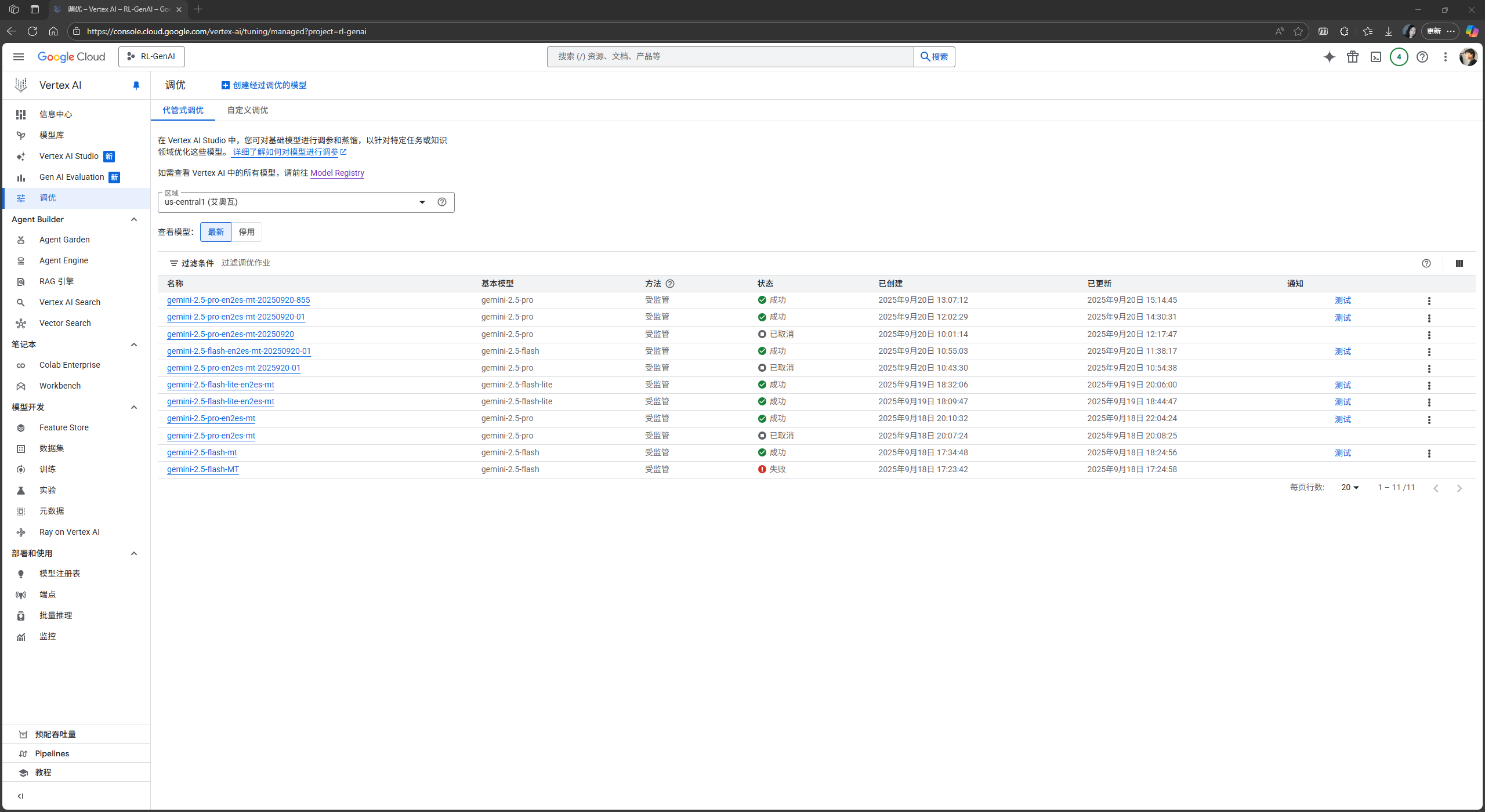
至此, 我们已经完成了
账户创建项目创建微调准备等预备工作, 接下来, 为了对 Gemini 应用 SFT 微调, 我们需要创建训练数据集. -
数据预处理与数据集构建
这部分主要涉及本地的数据处理逻辑, 不同下游任务所需的数据预处理逻辑均不相同, 我也就不展示我的预处理 notebook 了. 在这一环节, 最重要的是 Gemini 所接受的数据集格式, 在官方文档中, 官方给出了各种不同的数据集格式, 十分杂乱, 且文档还停留在
Gemini1.0时代, 令人忍俊不禁, 在扒开了GenAISDK 的源代码后, 我终于找到了 Gemini 的训练集格式, 具体格式如下:首先, 训练集文件应当是一个
.jsonl文件, 每行一个json schema, 依次排列.对于其中一个 json schema 则是一条训练数据, 其格式如下:
{"contents": [{"role": "user", "parts": [{"text": "Your prompt string"}]}, {"role": "model", "parts": [{"text": "The output which is supposed to be generated by model."}]}]}当然, 你也可以在其中加入
system消息和多轮对话消息, 这取决于你的下游任务场景.最终, 你应该处理出这样一个
.jsonl文件, 作为Gemini的训练集:# train_set.jsonl {"contents": [{"role": "user", "parts": [{"text": "Your prompt string"}]}, {"role": "model", "parts": [{"text": "The output which is supposed to be generated by model."}]}]} {"contents": [{"role": "user", "parts": [{"text": "Your prompt string"}]}, {"role": "model", "parts": [{"text": "The output which is supposed to be generated by model."}]}]} {"contents": [{"role": "user", "parts": [{"text": "Your prompt string"}]}, {"role": "model", "parts": [{"text": "The output which is supposed to be generated by model."}]}]} -
使用数据集对 Gemini 模型应用 SFT
回到 GCP 的 Vertex AI 页面, 找到页面上部的
创建经过调优的模型按钮并点击:
你会进入模型微调作业配置页面:
谷歌云的网页元素中翻一言难尽, 不过看得懂就好了.
在这里你可以选择本次微调作业的基线模型, 并设置微调后的模型名称, 在这里我的下游任务是机器翻译 (MT, Machine Translation), 故将我的模型命名为
gemini-2.5-pro-mt: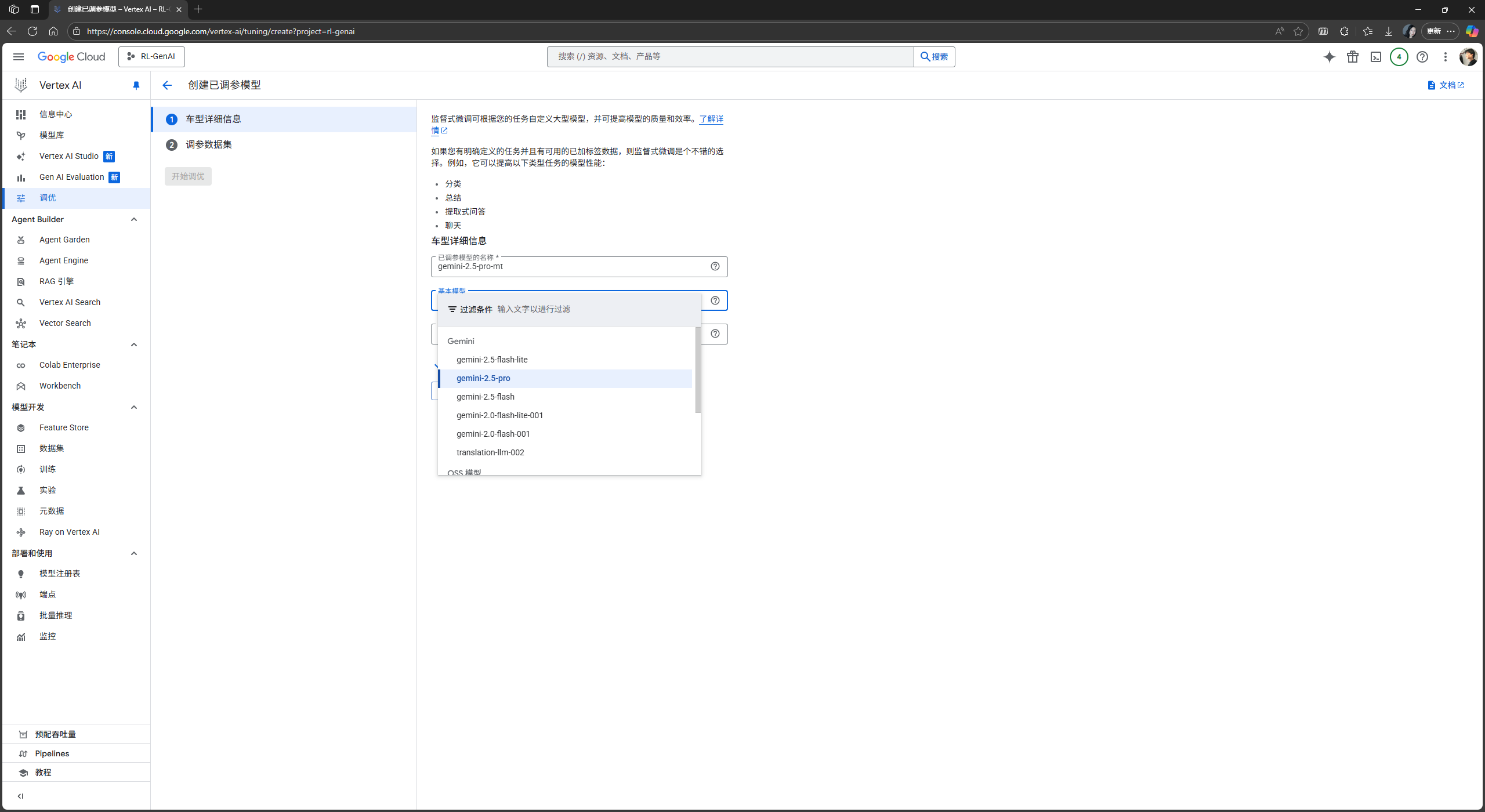
如果你是一个十分熟悉 SFT 微调的人 (像我一样), 你可以选择打开
高级选项, 配置周期数 (即 Epochs)学习率系数和适配器大小 (即 LoRA Adapter 矩阵的秩). 当然, 如果你不设置这些训练参数,VertexAI会为你自动实验, 生成理论上最合适的训练参数, 多数情况下比你手动设定的参数更优.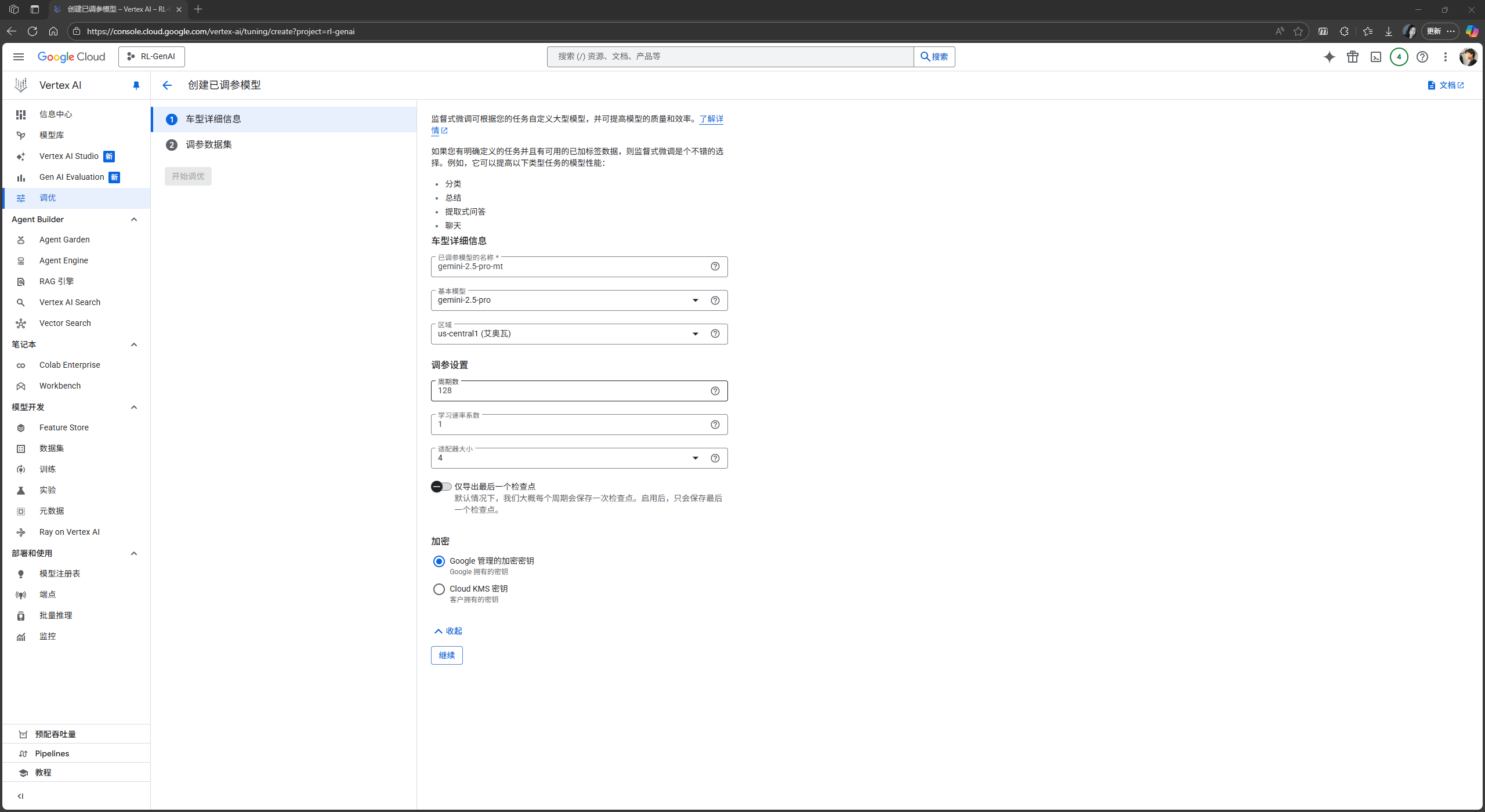
接下来, 你需要上传数据集:
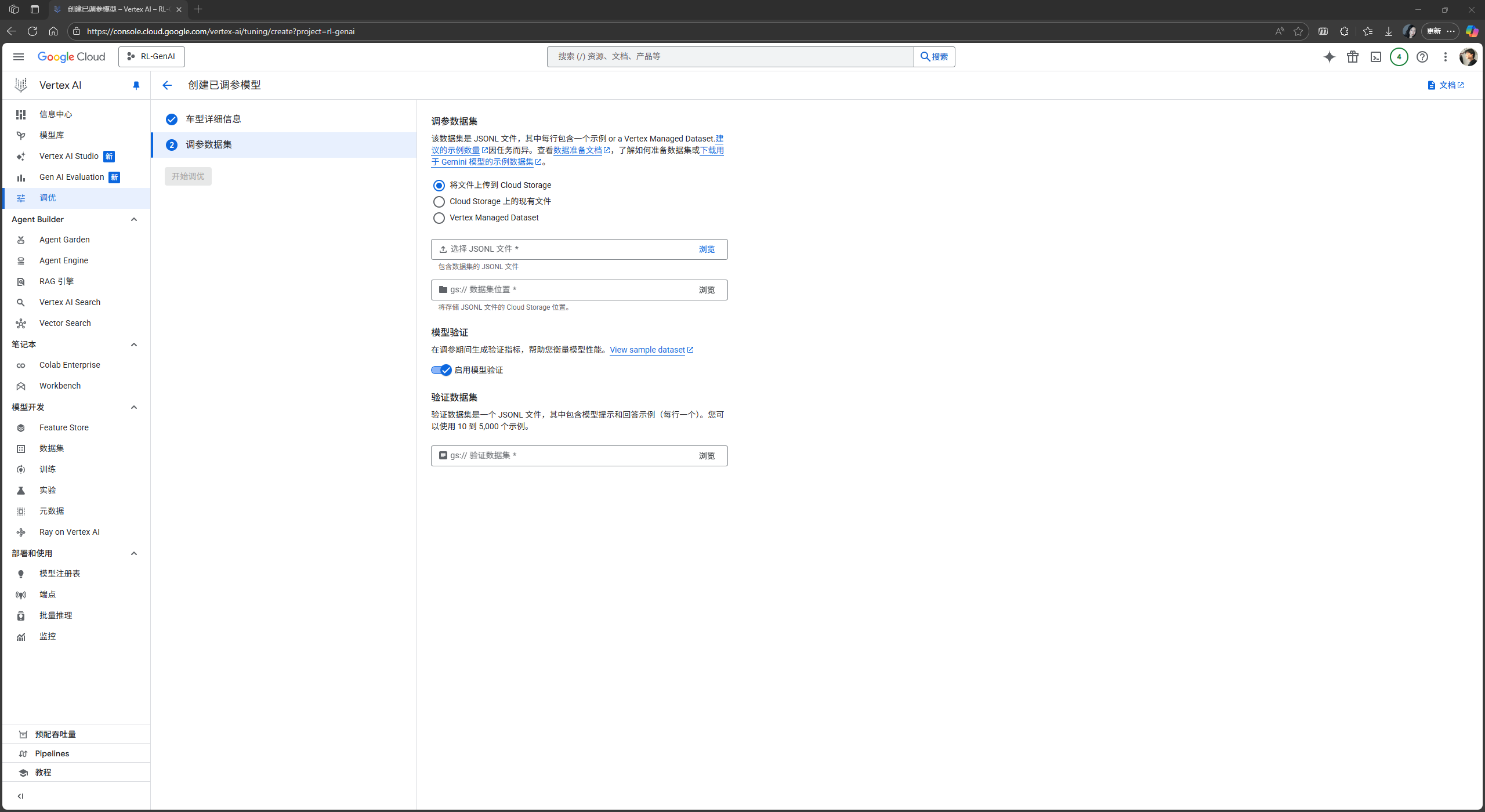
浏览并上传你的
.jsonl训练集文件, 并选择或创建一个Cloud Storage存储路径以存储你的数据集: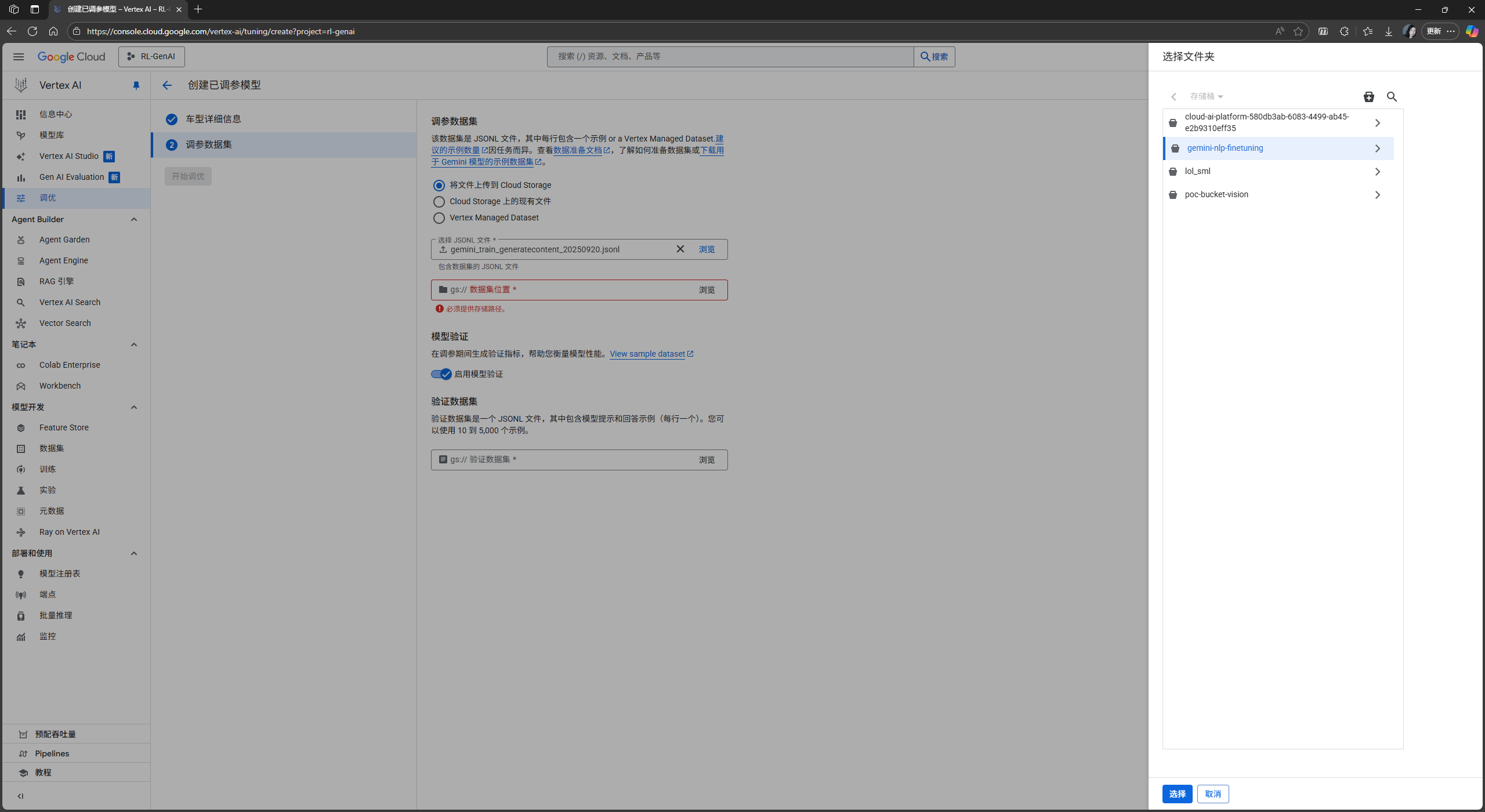
上传完毕后, 点击
开始调优按钮, SFT 就正式开始了: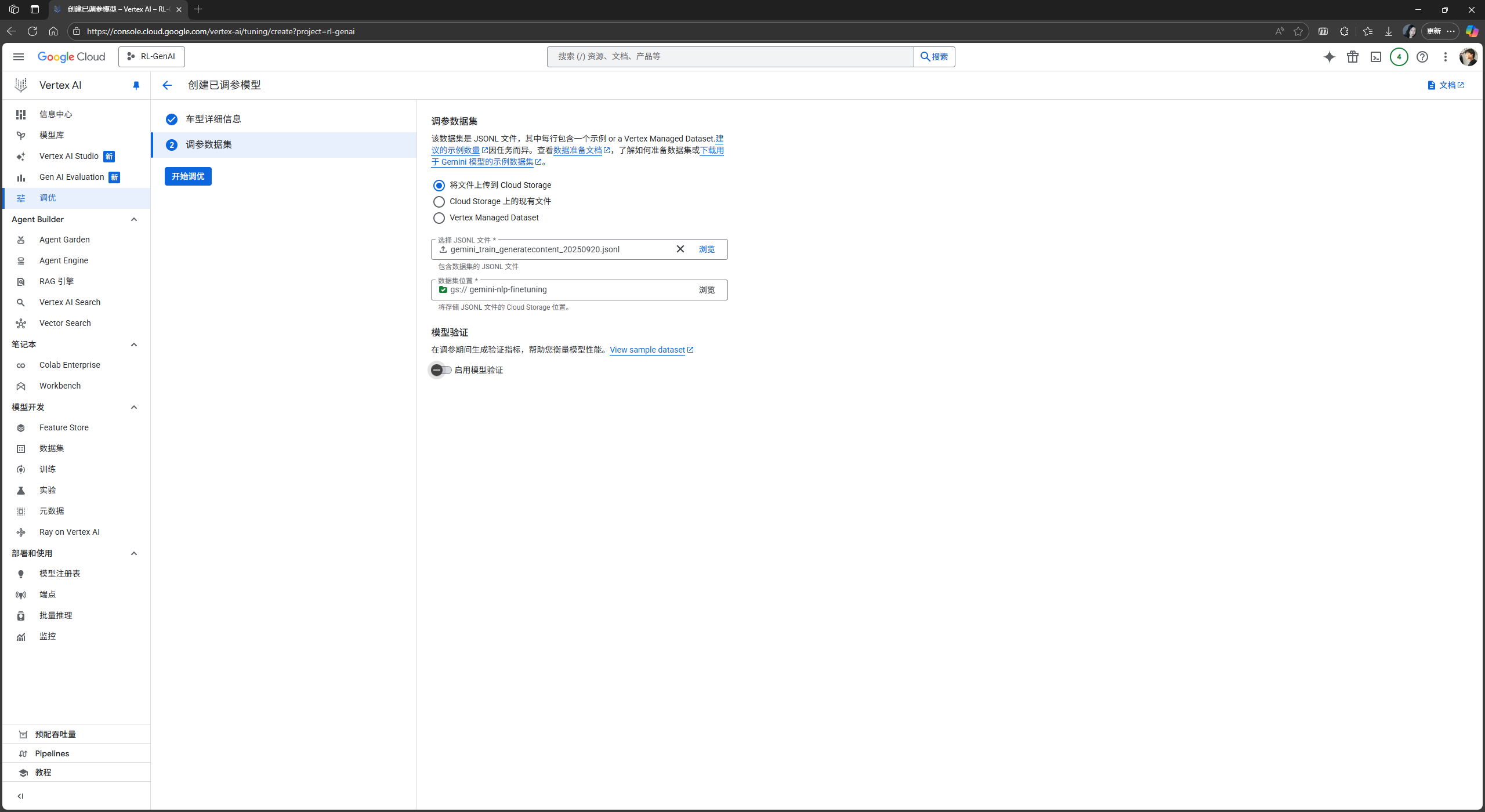
-
调用训练后的模型, 开发你的下游任务算法与工作流
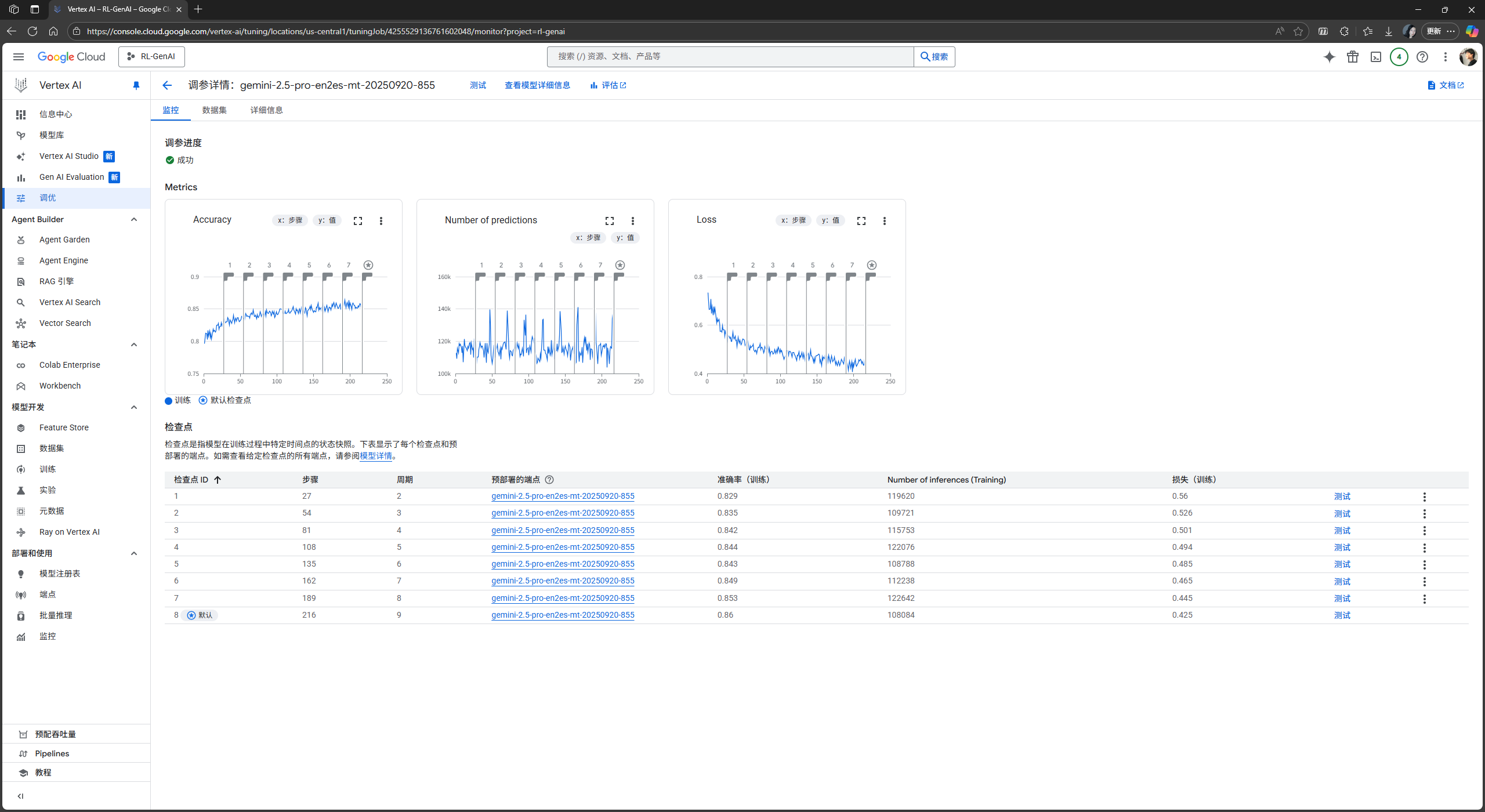
训练完成后, 页面将如下呈现训练结果 (包括准确率, 预测数量, 和损失值):
这里的准确率, 指的是以 token 为单位的 next token 预测准确率; 预测数量指的是一轮完整的自回归生成中, 预测的所有 next token, 即生成的总 token 量; 而损失值指的是单次 next token 生成预测时, 生成 token 分布和训练集该位置 token 分布的交叉熵.
从
详情信息模块中查看本次微调作业的唯一标识符: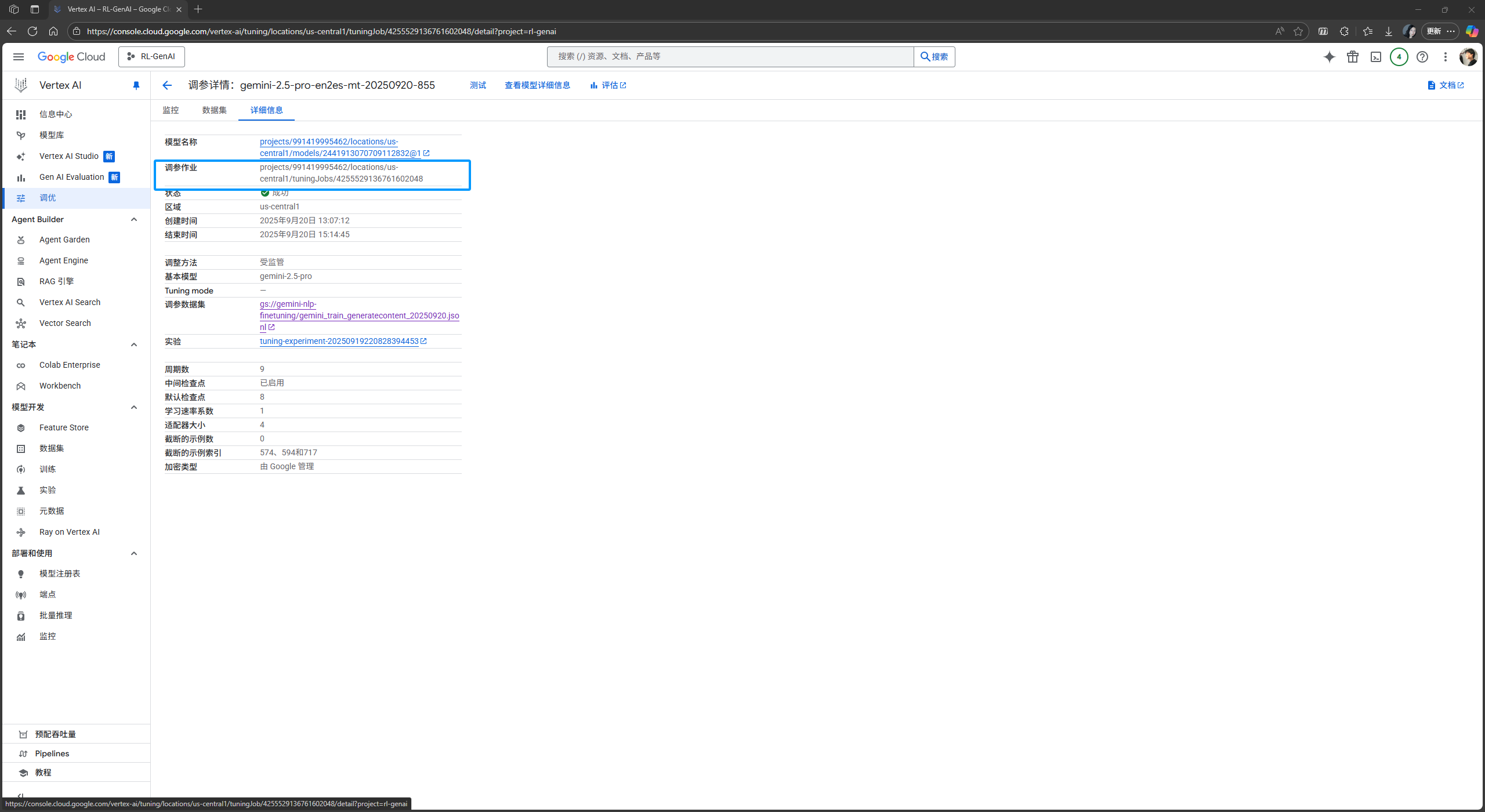
此处, 我的任务标识符为
projects/991419995462/locations/us-central1/tuningJobs/4255529136761602048, 通过该标识符, 我们可以通过 GenAI SDK 调用经微调的模型.在进行调用之前, 我们还需生成 GenAI SDK 客户端所需的鉴权凭证.
返回谷歌云主页, 访问
IAM 和管理模块:
进入
IAM模块后, 点击服务账号子模块, 找到创建服务账号按钮并点击:之后你会进入创建服务账号的流程, 并得到一个服务账号
创建完毕后, 点击刚刚创建的服务账号
然后找到并点击
密钥按钮:
点击
添加键按钮, 并选择 JSON 格式, 由此, 你的凭证创建完毕并自动下载:
接下来, 转到 Python 项目代码:
-
首先安装必要的依赖包
uv add google-cloud-aiplatform>=1.71.1 google-genai>=1.38.0 vertexai>=1.71.1 -
创建 VertexAI 客户端
import os from google.genai import Client VERTEX_PROJECT_ID = 'rl-genai' # 这里要和你的项目名一致 VERTEX_LOCATION = 'us-central1' # 这里要和微调作业的服务器地区一致 (默认美中, 爱荷华州服务器) os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = './rl-genai-c081d5f3bedc.json' # 这里配置的是: 刚下载的凭证文件的路径 client = Client(vertexai=True, project=VERTEX_PROJECT_ID, location=VERTEX_LOCATION) -
配置推理超参数和安全性过滤规则
from google.genai.types import GenerateContentConfig, HttpOptions, HarmCategory, HarmBlockThreshold, SafetySetting generation_config = { "max_output_tokens": 65536, "temperature": .01, "top_p": .01, "candidate_count": 1, "seed": 0 } safety_settings = [ SafetySetting( category=HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT, threshold=HarmBlockThreshold.OFF ), SafetySetting( category=HarmCategory.HARM_CATEGORY_HARASSMENT, threshold=HarmBlockThreshold.OFF ), SafetySetting( category=HarmCategory.HARM_CATEGORY_HATE_SPEECH, threshold=HarmBlockThreshold.OFF ), SafetySetting( category=HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT, threshold=HarmBlockThreshold.OFF ) ] gen_config = GenerateContentConfig( **(generation_config | {'http_options': HttpOptions(timeout=1_800_000)} | {"thinking_config": {'thinking_budget': 128}}), **{'safety_settings': safety_settings} ) -
发起推理请求
# 使用我们在 VertexAI 页面查到的微调作业标识符 projects/991419995462/locations/us-central1/tuningJobs/4255529136761602048 来获取微调作业实例, 并通过微调作业实例获取模型检查点 tuning_job_name = 'projects/991419995462/locations/us-central1/tuningJobs/4255529136761602048' prompt = ''' ## ROLE 你是一个以拉丁美洲西班牙语为母语的小说编辑, 你擅长对西班牙语小说进行精修. ## OBJECTIVE 思考如何对[翻译稿]进行精修, 仅输出思考决策过程细节. ## INSTRUCTION 摆在你眼前的有[原文稿]和[翻译稿], 我需要你深入思考如何对[翻译稿]进行精修. ## CONTEXT - **任务背景**: 我们的翻译同事收到了一份原文稿件([原文稿]), 并对其进行了初步的西班牙语翻译([翻译稿]), 但从英文翻译到西班牙语的[翻译稿]还是有很多细节对西班牙语母语者而言并不流畅地道, 所以现在需要你对[翻译稿]进行精修. ## INPUT - **原文稿**: Chapter 7 New Haircut After getting their nails done, Millie and Alexia treated themselves to a spa session. Later, after dropping Alexia off, Millie headed into a hair salon. The hair dresser gave her long, waist-length hair a thoughtful glance. "You're really cutting it all off? It looks great on you, you know." It was the kind of hair people paused to admire—thick, sleek, and clearly well looked after. - **翻译稿**: Capítulo 7 Un nuevo corte Después de la manicura, Millie y Alexia se consintieron con una sesión de spa. Más tarde, tras dejar a Alexia, Millie se dirigió a una peluquería. El estilista observó, pensativo, su larga melena, que le llegaba hasta la cintura. "¿Está segura de que quiere cortarlo todo?", preguntó él. "Le queda de maravilla, ¿sabe?". Era el tipo de cabello que hacía que la gente se detuviera a admirarlo: una melena densa, lisa y de un brillo saludable. ## OUTPUT_DATATYPE plaintext ## OUTPUT_FORMAT <think> ... </think> ## CONSTRAINT 输出以 "<think>" 开始 ''' resp = client.models.generate_content( model=client.tunings.get(name=tuning_job_name).tuned_model.endpoint, contents=[{'role': 'user', 'parts': [{'text': prompt}]}], config=gen_config ) print(resp.text)最后, 我们就能获得我们训练的模型的输出:
<think>现在我将以一个小说编辑的身份, 详细讲解我是如何将这份翻译初稿精修成最终稿的. 我的目标是让文本不仅仅是“正确”的, 更是要让它在节奏、语感和文学性上都达到母语者的阅读标准. 对于语句的取舍和调整, 我会结合上下文、人物关系和叙事节奏来解释我的思路.我们开始吧.**第一句:*** **翻译稿**: `Después de la manicura, Millie y Alexia se consintieron con una sesión de spa.`* **我的精修思路**: * `Después de la manicura` -> `Después de hacerse las uñas`: 原文是 "getting their nails done", 这是一个动作. `la manicura` (美甲) 是一个名词, 指的是服务本身. `hacerse las uñas` (做指甲) 是一个动词短语, 更准确地表达了她们“做了指甲”这个动作, 语感更动态、更口语化. * `se consintieron con una sesión de spa` -> `se regalaron una sesión de spa`: `Consentirse` (纵容自己) 是正确的, 但在西班牙语中, 当我们谈论为自己买东西或享受服务作为一种奖励或款待时, `regalarse algo` (给自己送一件礼物) 是一个非常地道且富有情感色彩的表达. 它暗示这是一种特别的、珍贵的自我犒劳, 文学性更强.**第二句:*** **翻译稿**: `Más tarde, tras dejar a Alexia, Millie se dirigió a una peluquería.`* **我的精修思路**: * `tras dejar a Alexia` -> `después de dejar a Alexia`: `tras` 和 `después de` 都是“在...之后”的意思. 但在日常叙事中, `tras` 显得稍微正式或书面化一些. `después de` 更为通用和自然, 能让叙述的节奏更流畅. * `se dirigió a una peluquería` -> `entró en una peluquería`: 原文是 "headed into a hair salon". `dirigirse a` 意为“前往”, 描述的是方向和意图. 而 `entrar en` 意为“进入”, 描述的是一个已经完成的动作. 后者更具体, 画面感更强, 直接将场景切换到了理发店内, 推动了情节发展.**第三句:*** **翻译稿**: `El estilista observó, pensativo, su larga melena, que le llegaba hasta la cintura.`* **我的精修思路**: * `El estilista` -> `El peluquero`: `Estilista` (造型师) 通常指更高端、更注重时尚设计的发型师. `Peluquero` (理发师) 则更普遍、更接地气. 考虑到这只是一个普通的场景, `peluquero` 更符合情境, 避免了不必要的拔高. * `observó, pensativo, su larga melena` -> `le echó un vistazo pensativo a su larga melena`: `Observar` (观察) 是一个比较正式、持续时间较长的动作. 原文 "gave her... a thoughtful glance" 描述的是一个短暂而专注的“一瞥”. 西班牙语习语 `echar un vistazo` (看一眼) 完美地捕捉了这种瞬间感. 将 `pensativo` (深思地) 放在 `vistazo` 之后, 结构更紧凑, 节奏感更好. * `que le llegaba hasta la cintura` -> `que le llegaba a la cintura`: 这是一个细微但重要的语感调整. `hasta` (直到) 带有强调终点的意味, 而不加 `hasta` 的 `le llegaba a la cintura` (长到腰部) 是一种更自然、更中性的描述, 听起来就像母语者会说的话.**第四句 (对话):*** **翻译稿**: `"¿Está segura de que quiere cortarlo todo?", preguntó él.`* **我的精修思路**: * `¿Está segura...?` -> `¿Estás segura...?`: 这是最重要的修改之一. 理发师和顾客之间, 尤其是在一个非正式的场合, 使用非正式的 `tú` (你) 而不是正式的 `usted` (您) 会显得更亲切、更有人情味. 这也符合拉丁美洲多数地区的社交习惯. * `cortarlo todo` -> `cortártelo todo`: 既然主语从 `usted` 变成了 `tú`, 相应的物主代词也要从 `lo` 变成 `te`. `Cortártelo` (你把它剪掉) 是正确的变位. * `preguntó él` -> `preguntó`: 在西班牙语小说中, 如果对话者的身份很明确 (这里只有理发师和Millie), 通常会省略主语代词 (`él`, `ella`). 这能让对话的归属标签 (dialogue tag) 更简洁, 使读者的注意力完全集中在对话内容上.**第五句 (对话):*** **翻译稿**: `"Le queda de maravilla, ¿sabe?".`* **我的精修思路**: * `Le queda de maravilla` -> `Te queda genial`: 同样, 将 `usted` 的用法 (`le`) 改为 `tú` 的用法 (`te`). `De maravilla` (极好地) 有点夸张和老派. `Genial` (很棒) 是一个非常现代、常用且充满活力的词, 更符合一个理发师的口吻. * `¿sabe?` -> `¿sabes?`: 同样是 `usted` 到 `tú` 的转换. 这个句末的 `¿sabes?` 就像英文的 "you know", 是一种拉近距离、寻求认同的口头禅, 非常自然.**第六句:*** **翻译稿**: `Era el tipo de cabello que hacía que la gente se detuviera a admirarlo: una melena densa, lisa y de un brillo saludable.`* **我的精修思路**: * `Era el tipo de cabello que hacía que la gente se detuviera a admirarlo` -> `Era el tipo de pelo que la gente se detenía a admirar`: * `cabello` -> `pelo`: `Cabello` 比较正式, 常用于科学或非常文雅的语境. 在日常和文学叙事中, `pelo` (头发) 更为普遍和自然. * `hacía que la gente se detuviera` -> `la gente se detenía`: 前者是“使动”结构 (make people stop), 语法正确但略显冗长. 后者是简单过去时 (people stopped), 描述的是一个习惯性的、反复发生的过去动作, 表达更直接、更有力, 节奏也更快. * `una melena densa, lisa y de un brillo saludable` -> `grueso, liso y claramente bien cuidado`: * `una melena densa` -> `grueso`: 原文是 "thick". `Denso` (密集的) 也可以, 但 `grueso` (粗的, 厚实的) 更能体现发丝本身的质感和发量的丰厚感. * `lisa` -> `liso`: 形容词需要与阳性名词 `pelo` 保持性数一致. * `de un brillo saludable` -> `claramente bien cuidado`: 原文是 "clearly well looked after". `De un brillo saludable` (有着健康的光泽) 是一个不错的意译, 但它只抓住了“健康”这一点. `Claramente bien cuidado` (明显被精心照料) 是对原文更精准、更全面的翻译, 涵盖了“明显”和“精心照料”两个层面的信息, 描述更丰富.</think>
-