最近看了一遍 InkOS 源码,重点看了 packages/core。这个项目表面上是一个“让 AI 自动写小说”的 CLI / Studio 工具 (类似 Claude Code, 可以认为是专业写小说的 Claude Code 工具),但真正有意思的地方不在“调用 LLM 写一章”这件事上,而在它怎么把长篇小说写作拆成一套可检查、可修订、可回滚的流程。很多 AI 写作工具的问题是:前几章还行,越往后越容易忘设定、丢伏笔、乱改角色关系,甚至把已经失去的物品又写回来。InkOS 的思路比较工程化:不要把全部希望压在模型的上下文窗口里,而是把小说拆成状态、规则、计划、正文、审计和修订几个环节。
用户界面
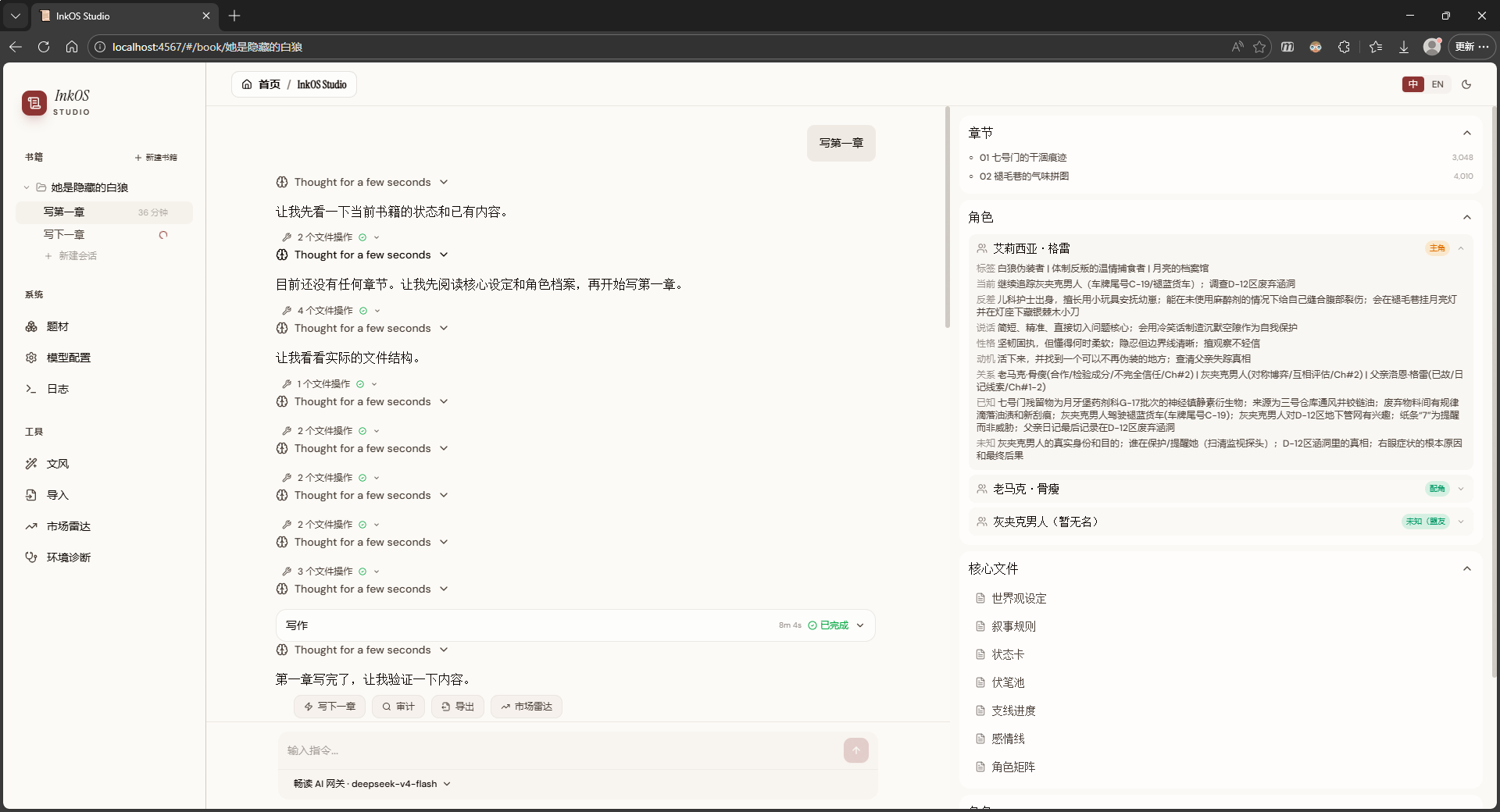
它到底是什么
InkOS 是一个 pnpm workspace,主要有三个包:
inkos
├── packages/core # 核心能力:建书、写章、审计、修订、状态管理、LLM 适配
├── packages/cli # 命令行和 TUI
└── packages/studio # Web 工作台,Hono API + React/Vite
最重要的是 packages/core。CLI、TUI、Studio 都是不同入口,真正的写作流程、模型调用、状态文件、审计规则、导入导出、同人和文风功能都在 core 里。
从技术栈看,core 使用 TypeScript ESM、Zod、@mariozechner/pi-ai 和 @mariozechner/pi-agent-core。Zod 用来校验配置和模型输出;pi-ai 负责把不同模型服务接到统一接口;pi-agent-core 用在新的可恢复 agent session 上。
一次“写下一章”发生了什么
如果只看用户体验,命令可能很简单:
inkos write next 吞天魔帝
但在内部,它不是直接把“请写下一章”发给模型。一次完整写章大致会走这些步骤:
1. 给书加文件锁,避免两个进程同时写同一本书
2. 算出下一章章号
3. 规划这一章要完成什么
4. 组装这一章需要看的上下文和规则
5. 写正文
6. 从正文里结算状态变化
7. 检查字数,必要时做一次归一化
8. 审计连续性、AI 味、敏感词、节奏疲劳等问题
9. 如果问题严重,进入修订
10. 保存章节、更新状态、创建快照、同步记忆索引
这套流程的关键点是:模型不是直接面对一大堆文件随便写,而是先由系统整理出“这一章真正需要知道什么”。这比把所有设定塞进 prompt 更稳定,也更容易排查问题。
先规划,再写作
InkOS 的输入治理主要由 Planner 和 Composer 完成。
Planner 负责回答一个朴素的问题:这一章到底要干什么?它会读取作者意图、当前焦点、卷纲、世界观、角色信息、最近章节摘要和可回收伏笔,然后生成两类东西:
chapter intent:这一章的目标、必须保留的设定、必须避免的内容。chapter memo:更细的章节备忘,用来约束写手不要偏题。
这里有一个细节值得注意:Planner 的 memo 不是随便信模型输出。源码里有严格 parser,解析失败会把错误反馈给模型,最多重试 3 次。也就是说,LLM 输出只是候选结果,必须过格式检查才能进入下一步。
Composer 接着把 Planner 的结果编译成运行时文件:
story/runtime/chapter-XXXX.context.jsonstory/runtime/chapter-XXXX.rule-stack.yamlstory/runtime/chapter-XXXX.trace.json
这三个文件解决的是可追踪性问题。它们回答:“这一章到底带了哪些上下文?”“哪些规则优先级更高?”“这些输入是怎么选出来的?”当章节写崩时,排查点就不只是“模型不好”,还可以看输入是否选错、规则是否冲突、planner 是否偏离。
README 中提到 plan / compose 可以用来先检查输入治理结果。源码里当前实现还有一个小口径差异:plan 阶段会调用 LLM 生成 memo;compose 在没有新上下文时可以复用已经保存的 plan。也就是说,它确实支持把规划和写作拆开,但“完全不依赖在线 LLM”这一点要看具体路径。
写正文和更新状态是两件事
WriterAgent 的设计比较清楚:创作正文和结算状态分开做。
第一阶段是写正文。模型拿到已选上下文、规则栈、章节备忘、字数要求、风格指纹、最近章节和角色信息,输出正文。这个阶段允许一定创作自由,温度也更高。
第二阶段是状态结算。系统会让模型从正文中提取变化,例如:
- 主角现在在哪里。
- 当前目标有没有变化。
- 哪些资源被消耗或获得。
- 哪个伏笔被推进、延后或回收。
- 本章摘要、情绪变化、支线变化是什么。
这一步输出的是 JSON delta,而不是让模型重写整份状态文件。代码会用 Zod 校验 delta,再通过 reducer 做 immutable apply。这样做的好处很直接:模型可以参与总结,但不能随手污染整本书的历史事实。
写完后还有一些不花 LLM 成本的规则检查,比如段落形态、跨章重复、AI 味表达、敏感词和伏笔健康度。这些检查不一定能替代编辑,但很适合当第一道自动防线。
长期记忆不是聊天记录
InkOS 最值得借鉴的地方是它不把“记忆”理解成聊天上下文,而是落到本地文件和结构化状态里。
第一层是人类可读的 truth files。README 里列了 7 个核心文件:
current_state.md:当前世界状态、角色位置、已知信息。particle_ledger.md:资源账本,记录物品、金钱、物资等。pending_hooks.md:未回收的伏笔和冲突。chapter_summaries.md:章节摘要和状态变化。subplot_board.md:支线进度。emotional_arcs.md:角色情绪和成长线。character_matrix.md:角色互动和信息边界。
这些文件对作者也友好。作者可以直接打开 Markdown 看系统记住了什么,也可以手动改。
第二层是 story/state/*.json。这是结构化权威层,使用 Zod schema 校验。比如伏笔状态只能是 open、progressing、deferred、resolved,章节号必须是整数。坏数据会被拒绝,不会悄悄写入。
第三层是 story/memory.db。它使用 Node 22+ 的 node:sqlite,保存 facts、chapter summaries 和 hooks,用来按相关性检索历史信息。这个数据库只是加速索引,不是唯一事实来源。如果当前 Node 运行时没有 node:sqlite,系统会退回 Markdown / JSON 路径继续工作。
这种三层设计很实用:Markdown 方便人看,JSON 方便程序校验,SQLite 方便检索。
审计不是“让模型点评一下”
InkOS 的审计维度比普通“帮我检查错漏”细得多。源码里 ContinuityAuditor 内置了 37 个维度,前 33 个覆盖普通原创小说,后面几个偏向同人和正典一致性。
常见维度包括:
- OOC,也就是角色行为是否崩坏。
- 时间线是否矛盾。
- 世界设定是否冲突。
- 战力和数值是否崩坏。
- 资源账本是否对得上。
- 伏笔是否拖太久、是否越权回收。
- 节奏是否停滞。
- 角色是否知道了不该知道的信息。
- 是否出现高频 AI 味词汇和公式化句式。
- 章节是否偏离 memo。
审计结果不是只有 LLM 判断。Pipeline 会合并 LLM continuity audit、AI 痕迹分析、敏感词检查和长跨度疲劳检测。失败后再交给 Reviser。
Reviser 也不是一上来就整章重写。它有多种模式:
spot-fix:只改具体句子或段落。polish:润色表达。rewrite:局部改写。rework:更大范围重做。anti-detect:降低 AI 生成痕迹。
源码里还会按问题类型决定是输出局部 patch,还是输出完整修订稿。这个细节很重要。长篇写作里,大改很容易引入新矛盾;能局部修就局部修,反而更安全。
不只是写新书
README 里强调的几个核心特性,在源码里都有对应落点。
文风仿写:style analyze 会分析参考文本,提取句长、段落长度、词频、句式和风格指南。style import 会把这些结果写入书籍,后续 Writer 和 Reviser 都可以使用。
续写已有作品:import chapters 可以导入已有章节,再反向生成或更新 truth files,让系统从既有内容继续写。导入时还会处理章节切分、摘要、状态快照和记忆索引。
同人创作:fanfic init 会从原作素材生成 fanfic_canon.md,支持 canon、au、ooc、cp 等模式。审计阶段也会加入同人专属维度,比如正典事件一致性、世界规则遵守、角色还原度和关系动态。
雷达:Radar 用来扫描市场趋势和读者偏好。它不是写章主链路的必需项,但可以作为题材和方向输入。
守护进程:inkos up 会启动后台循环写作。Scheduler 会定时写章、跑 radar,并在连续失败后暂停某本书。通知支持 Telegram、飞书、企业微信和 Webhook,Webhook 还支持 HMAC-SHA256 签名。
这些功能说明 InkOS 不是一个单点“续写器”,而是在往完整内容生产工具靠近。
CLI、TUI、Studio 共用同一个脑子
InkOS 的入口很多:
- CLI 原子命令:
plan、compose、draft、audit、revise、export等。 - Studio:Web 工作台,支持书籍管理、章节审阅、模型配置、真相文件编辑、AIGC 检测、数据分析、导入和同人。
- TUI:终端里的全屏交互仪表盘。
inkos interact:给外部 Agent 用的 JSON 入口。- OpenClaw Skill:README 里也明确推荐外部 Agent 优先走共享交互入口。
这些入口背后有一个共享 interaction runtime。自然语言请求会先被解析成意图,例如继续写、创建书、导出、改名、更新作者意图、更新当前焦点、写 truth file 等,然后再调用确定性的项目工具。
这比“每个入口自己实现一遍逻辑”更稳。比如 TUI、Studio 和外部 Agent 都要支持“把林烬改成张三”,就应该走同一个 rename tool,而不是三套替换逻辑。
当然,源码里仍然能看到演进中的痕迹:旧式 pipeline/agent.ts、新式 agent-session.ts、CLI 原子命令和 Studio API 并存。这个项目已经在收敛到共享内核,但历史路径还没有完全消失。
模型配置做得很细
InkOS 的 provider bank 是另一个容易被忽略的工程点。
README 里提到它内置了 Google Gemini、Moonshot、MiniMax、智谱、百炼、DeepSeek、硅基流动、PPIO、OpenRouter、Ollama、CodingPlan 等服务。源码里这些服务有自己的 endpoint、模型列表、协议、兼容策略和推荐 transport。
它处理的问题包括:
- service 和 model 是否匹配,避免把 Kimi 模型发到 Gemini 服务。
- baseUrl 如何推导。
- 使用 chat 还是 responses 协议。
- 是否启用 streaming。
- 哪些模型参数要过滤,避免用户配置覆盖核心请求字段。
- Google Gemini 这类 OpenAI-compatible endpoint 的兼容差异。
- MiniMax 这类服务在流式和非流式上的行为差异。
doctor如何展示当前 effective config 和连通性。
Studio 和 CLI 的配置也被刻意分开。Studio 优先使用项目内服务配置和 .inkos/secrets.json;CLI、daemon 和部署环境可以叠加全局 env、项目 env、进程环境变量和命令行参数。这个设计牺牲了一点简单性,但能避免“我在 Studio 配好的服务被某个 .env 悄悄覆盖”。
我喜欢的地方
第一,它把长篇写作当成状态管理问题,而不是聊天问题。小说越长,越不能只靠模型记忆。
第二,它对 LLM 输出保持怀疑。Planner memo、runtime delta、hook record、项目配置都有 parser 或 schema 保护。模型负责生成候选内容,代码负责验收。
第三,它保留了人类可读层。很多 Agent 系统把状态藏在数据库里,作者很难理解系统到底记住了什么。InkOS 让 Markdown truth files 成为工作台的一部分,这对创作工具很重要。
第四,它有快照和回滚。长篇写作一定会出现坏章。只重写文本不够,状态也要能回到某个章节之前。
第五,它把模型兼容集中在 provider 层。不同服务商的协议差异、streaming 差异、max token 和特殊参数如果散落在 agent 里,后期会很难维护。
主要风险
第一个风险是 PipelineRunner 太大。它承担了建书、写章、导入、同人、文风、状态同步、审计修订、记忆索引、通知等很多职责。短期这样开发快,长期会让修改成本升高。
第二个风险是入口多。CLI、Studio、TUI、旧 agent loop、新 agent session 都能触发类似动作。只要某个入口少做一个 guard,就可能行为不一致。共享 interaction runtime 是正确方向,但还需要继续收敛。
第三个风险是兼容层复杂。Markdown 和 JSON 双写、旧 layout fallback、SQLite 可选、不同模型协议、Studio / CLI 配置隔离,这些都实用,但每一层都会带来边界条件。
第四个风险是用户理解成本。比如 memory.db 依赖 Node 22+ 的 node:sqlite,而 package engine 是 Node >=20。代码会降级,但用户可能不知道为什么自己的环境没有 SQLite 加速。
最后
InkOS 最有价值的地方不是“它能不能写出一本好小说”。小说质量最终仍然取决于设定、审美、模型能力和人工审阅。
它真正值得研究的是另一件事:怎么把一个模糊的 LLM 创作任务,拆成可以检查的步骤。
在 InkOS 里,作者意图、当前焦点、卷纲、角色关系、伏笔、资源账本、章节摘要、审计结果和修订动作都被文件化、结构化、流程化。模型不再是一个独自发挥的黑箱,而是流水线里的一个参与者。
这个模式不只适合小说。任何长周期内容生产,只要存在“上下文很长、状态会变化、错误会累积、需要审计和回滚”的问题,都可以从 InkOS 里借鉴一些设计。